


Builds & Breakthroughs #1
Each week, we share what AI models just unlocked and what builders are doing with it.


Build: Peek – Your AI money ops room
Builder: Sherry Jiang

What it does
AI workspace that turns raw finance data into concrete money moves—no spreadsheets.
“Instead of dashboards, we turn their transaction data into behavioral nudges that drive action - delivered through Gen Z-friendly interfaces like reels and chat.”
Breakthroughs
Cheaper tokens + larger context windows kill RAG. Full ledgers now sit in-prompt, and Peek ingests 24 months of transactions on day one.
“Cost drop + larger context window helps us achieve a lot of things. Analyzing 2 years worth of transactions in the first 5 mins of users onboarding onto Peek (after connecting Plaid) was not possible with our version 1 because gemini wasn't as good back then. we had to scope down requests to 1-2 months of transaction data. It also means we save cost on infrastructure since we don't need things like RAG and everything can be loaded into the context window directly.”
Backend flipped to “thin shell.” LLM now runs portfolio math, savings logic, and drives the UI; every layer is exposed as a callable tool.
“We had to preprocess everything - portfolio math, savings calcuations, even basic categorization logic ran on the backend, because the models couldn’t handle it cleanly.”
Groq’s Llama 8B cleans thousands of descriptions in under 10s and answers chats in under 5s.
“Users are impatient - they are expecting <5 second chat responses + <5 min total time to finish task. there's something to be said about UX when users can quickly get analysis done across large data sets. newer models like gemini helps us achieve that.”
Stack
Models: Gemini 2.5 Pro, GPT-4o-mini, Llama-3.1-8B-Instant (Groq)
Memory: Zep long-term store injected on demand
Infra: Next.js on Vercel, serverless functions, Plaid & Alpaca APIs
Architecture: Backend = thin controller.
Still janky
Native, in-model memory is thin; external stores add fragility.
"Native memory support from model providers is still lacking. Right now we use external memory services (like Zep) and manually inject context - adds overhead, increases fragility, and creates a single point of failure.”
TypeScript agent tooling & eval libs trail Python.
"Too much of the good tooling lives in Python. understandable - ML engineers live there. but the web runs on TypeScript. if you're building agentic UX or real-time LLM interactions, you're stuck reinventing wheels or writing your own wrappers.”
Finance-specific evals are home-grown (catching hallucinated CAGR or bogus advice).
"Eval infra for financial correctness is almost nonexistent. We're hacking together our own tools to catch hallucinations in money-specific domains (e.g., miscalculated CAGR, incorrect portfolio suggestions). not ideal.”
Unlocks
Data-to-Action agents: Instead of dashboards, the agent pushes prescriptive steps (“cancel X”, “invest Y”).
Full-dataset in-prompt: Cheap tokens + big windows let you drop RAG and feed entire ledgers (or logs, telemetry, CRM history) straight to the model.
Thin-shell backends Off-load domain math (CAGR, cohort LTV) to the LLM; server code becomes a lightweight controller.
Promptable UI surfaces Every screen is exposed as a callable tool, so the model can edit state directly—no middle-layer glue.
Try it: Peek
Build: Metrica – Your AI Endurance Coach
Builder: Max Grigoryev
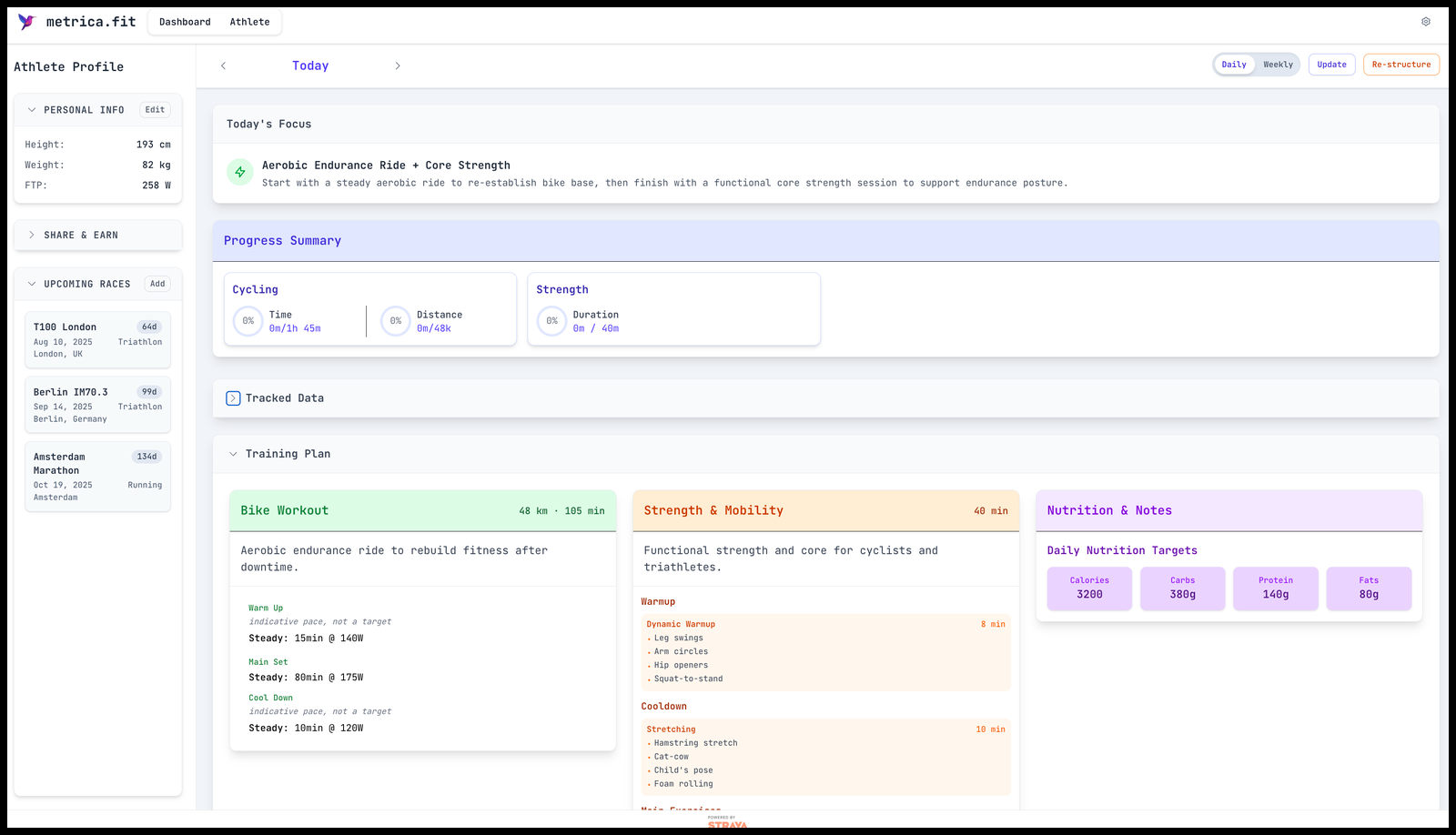
What it does
Adaptive training + nutrition plans for swim, bike, run, and strength—rebalanced daily from your performance.
“It doesn’t just build a training plan — it adapts in real time to how you feel.”
Breakthroughs
Embedded sports-science expertise: GPT-4.1 understands endurance, HRV, and recovery at coach level.
“New OpenAI GPT 4.1 model contains a lot of research data around endurance in general, heart rate behavior, recovery and it can align the plans based on individual factors.
Long-horizon planning: Larger context windows enable 12-week periodization without prompt chaos.
“Previous versions were good, but not as good as current one with long term planning.”
Full log in context: Cheaper tokens let Metrica load an athlete’s entire training history day one.
Stack
Infra: Supabase + Vercel
Models: Claude 3.5 Sonnet, GPT-4.1 (primary for training logic), Gemini 2.5 for coding
Coming soon: OpenAI Codex for dev assist, Whoop + Garmin integration (pending API access)
Still janky
Long-term memory & progression tuning still brittle.
“Generally speaking - context windows, but it improved with Sonnet 4 and also going to try Codex of OpenAI as well which would address some of coding challenges.”
Needs full wearable data for deeper personalization.
Unlocks
GPT-4.1 can simulate expert-level expertise once off-loaded to backend code.
Dynamic re-tuning: AI-generated plans can re-tune to subjective states (e.g. fatigue, motivation).
Whole-history context: Long-horizon planning is now viable with richer embedded knowledge + larger context windows.
Pro-grade guidance at consumer latency: Sub-second replies turn “expert report” into an interactive advisor.
Try it: Metrica
Build: Nelima – Your Agentic Personal Assistant
Builder: James Kachamila

What it does
Full agent that chains scraping, scheduling, and editing across tools like a power VA.
“She pulls KPIs from your database, spins up cold email campaigns, chains tasks across tools, and just gets it done — all from a prompt.”
Breakthroughs
Human-paced interaction: GPT-4o’s sub-second reasoning and voice/vision I/O finally make agentic workflows feel like working with a human teammate.
Custom SWARM: A SWARM router hands each sub-task to the best model, Claude 3.5, Gemini 2.5, or a fine-tuned LLaMA 3, boosting accuracy while reducing cost.
“The combo of GPT-4o’s real-time reasoning, memory, and multi-modal input/output made it finally viable to run agentic workflows that feel human-like, responsive, and somewhat reliable at scale. Note that we do use other models as well.“
Stack
Node.js backend + MongoDB (w/ vector store), Docker
Deployed across Azure + GCP (Cloud Storage + Compute)
BrightData for proxy routing, SerpAPI for scraping, μWebSocket for real-time comms
AI orchestration: GPT-4o, Claude 3.5, Gemini 2.5, LLaMA 3 (QLoRA), Voyage AI for embedding search
Still janky
Long-chain drift: The agent still forgets context and breaks on extended workflows.
Needs: durable memory, stronger tool-calling APIs, and models that honor system prompts even in huge context windows.
“We still run into friction with long-term memory and cross-task continuity, especially when chaining very complex actions over time. Many AI models lack persistent state or structured memory, which limits reliability in complex workflows.”
Unlocks
Human-paced multimodal execution: sub-second voice, vision, and text I/O, enabling continuous, conversational task chains.
Model-specialist orchestration: a SWARM router assigns each sub-task to GPT-4o, Claude 3.5, Gemini 2.5, or a fine-tuned LLaMA 3, balancing speed, quality, and cost.
Tool-chain autonomy: structured function calls let the agent scrape data, update databases, schedule events, and edit documents without manual glue code.
Infra-level reliability: retries, fallbacks, and persistent state maintain context across long, multi-step workflows.
Demo: Watch here
Try it: sellagen.com/nelima
X: @nelima_ai
Reddit: use case post
Your Turn
Built something on the frontier recently? Hit reply with the details. We’ll feature the best one next edition.
Amazing concept and execution, thanks!
This is great!