


Builds and Breakthroughs #2
Behind the build: what’s working, what’s powering it, and what’s still breaking. This week: always-on Scouts, remembers-everything doctors, a design-risk scanner for hardware, and AI astrologers.


Build: Scouts by Yutori
Always-on Scouts watch the web so you don’t have to
Builders: Abhishek Das, Devi Parikh, Dhruv Batra
Scouts are always-on AI agents that monitor dozens of sites in parallel - without touching your device.
Double click
“Tell Scouts what to track—papers on multimodal research, Tokyo flights under $900, price drops on Switch 2—and the agents ping you the moment it happens.”
Each Scout lives in the cloud, continuously scanning full web pages (text, tables, images) using post-trained multimodal models. They only notify on change events and conditions, all specifiable in natural language, so pings stay timely.
Breakthroughs
Technical or conceptual advances
Cloud swarm architecture: 24/7 parallel monitoring → complete coverage
Asynchronous orchestration: Scouts sleep until a change, then notify you → zero misses
Multimodal full-page parsing: Models read entire pages → no brittle CSS selectors
Fully cloud-native logic: All state & compute in the cloud → zero local load
Unlocks
What those breakthroughs make possible
Always-on agents: Continuous monitoring with no browser tabs or local scripts.
Resilient page parsing: Layout tweaks can’t break your monitors.
Thin client UX: All logic lives server-side; UI is just a watchlist.
Event-driven notifications: Updates push the moment they happen; no cron polling needed.
Stack
What’s under the hood
Models: Post-trained open-weight MM models (like LLaMA), Claude, GPT, Gemini
“There are many points in our stack where we use AI models -- some we train in-house, and some from existing frontier LLMs (GPT, Claude, Gemini).”
Infra: Vercel · Python · DBOS · Neon · Clerk · Modal · Bright Data
Why it matters
The big picture shifts
Pull → push internet: Scouts flips search from manual checks to automatic alerts.
Consumer-grade monitoring: Anyone can monitor dozens of pages without scripts or engineering help.
Layout-proof parsing: No more breakage from CSS tweaks or UI shifts. Multimodal models read pages like humans do.
Zero local load. All compute lives in the cloud; laptops stay idle and battery-friendly.
Less noise. Event-driven pings land the moment data changes—no polling, no stale results.
Try it
Watch the launch video
Read the blog post
Join the waitlist to spin up your first Scout today
Build: Eureka Health – the “do” layer for AI medicine
Builders: Sina Hartung, Zain Memon
Paste your health history or symptoms, and Eureka
’s AI doctor not only explains what’s going on—it orders labs, writes scripts, and tracks results in-app.
All your past records stay in context, so you never have to repeat your history.
“Ever asked ChatGPT for health advice? It’s good until you need to actually do something. We’re the “do” layer on top of today’s most powerful thinking models.”
Breakthroughs
Technical or conceptual advances
Big-context models: Gemini 2.5 + OpenAI o3 fit labs, imaging, wearable data, and past notes in one prompt, so advice always knows your full history.
“Context matters, many of our patients have insane amounts of health data (labs, imagining, reports, wearables) so increased context windows allow us to keep this info in memory.”
Chain-of-thought you can follow: Users watch the model explore every branch of a differential, which builds trust and lets power users dig deeper.
“Chain of thought and “thinking” really matters in healthcare. Especially many of our early adopters already consider themselves experts on their condition so they don’t want the super quick 1 liners.”
Agents inside the healthcare maze: Backend agents talk to Quest, Apero, Dosespot, and other legacy portals, turning ideas into orders while doctors stay in the loop.
“Agents plugged into our medical infrastructure make executing on the doing aspect of Eureka possible: whereas before we needed to integrate all our workflows manually (think: prescription portal, edge cases for compound drugs, different lab orders, lab providers, etc all of those are entirely different systems that don’t talk to each other and have old legacy tech), we can now allow an agent to “figure it out.”
Unlocks
What those breakthroughs make possible
Labs, prescriptions, and follow-ups issued directly from the chat.
Personalised plans with entire medical history in context; no more re-entering details.
“Concretely this means the advice is way better (esp. compared to previous models and less context) and more personalized (it feels nice to have the model remember that you’re on drug XYZ instead of having to remind your doctor!).”
Transparent reasoning helps patients vet each step.
Frontend can stay UX-focused; agents handle messy integrations behind the scenes.
Stack
What’s under the hood
App: React Native · Expo · Supabase
Models: Gemini 2.5 + OpenAI o3 (core reasoning) · GPT-4.1 (chart updates) · Claude 4 Sonnet (dev helpers)
Medical infra: Quest interface · Apero · Dosespot · Develop Health
Admin: TanStack Start + React backend
Still hard
What could be better
Agent SDK hand-offs can be unstable and unpredictable at times
Little tooling for multi-step, patient-level evals
“Better eval tooling: it’s really hard to build multi-step evals across a variety of healthcare tasks, and the tooling that does exist is seldom patient oriented and more clinical in nature.”
Wearable data import is pricey and incomplete.
“Prompt-your-own-app” is early; few standards to build on.
“Prompt your own app still early: early days, we see lots of promise in a reconfigurable app for the users built by the user, currently hard to do since there’s little precedent but that’s what will happen to a lot of consumer apps over the coming years.”
Why it matters
The big picture shifts
Turns AI health chats into real action—tests, meds, follow-ups—inside one app.
Shows large-context LLMs can outperform human recall for chronic care.
Demonstrates how agent orchestration can tame legacy healthcare portals without crippling the user experience.
Build: Niyam
AI design-risk scanner for hardware teams
Builders: Agrim Singh, Samarth Shyam
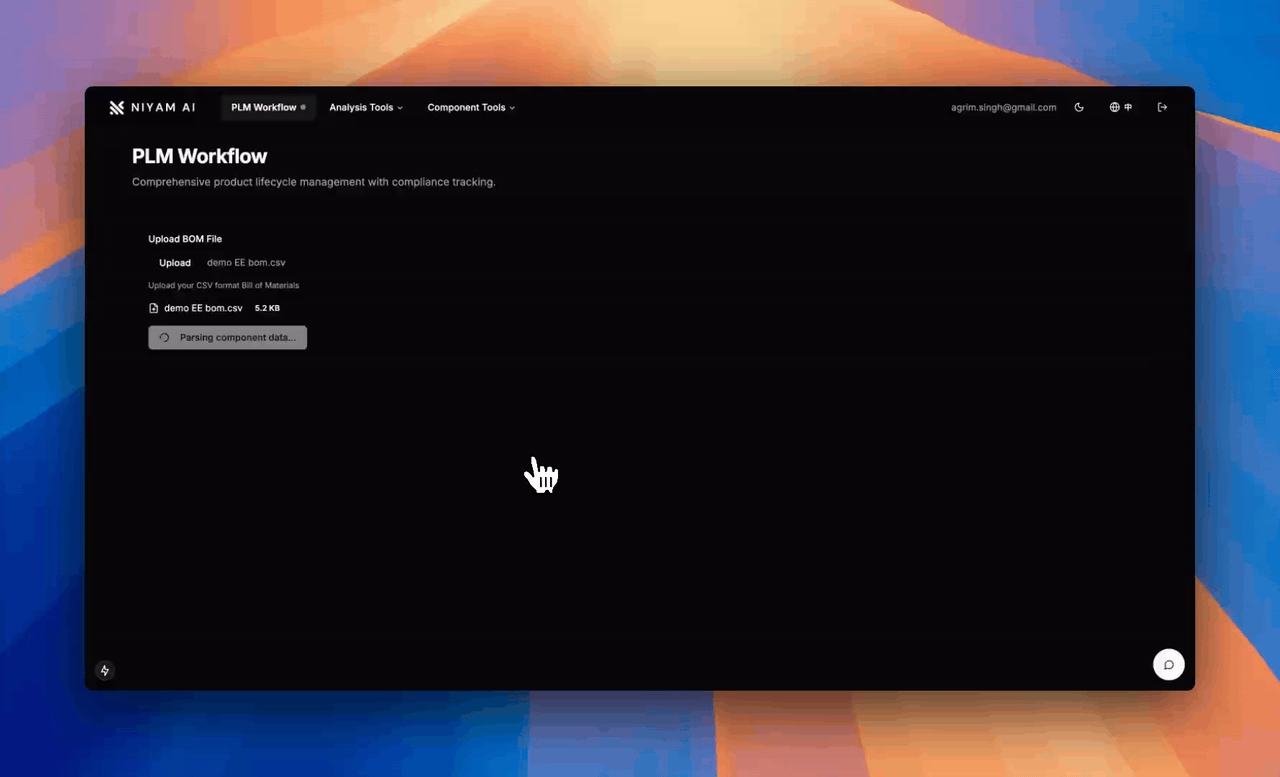
Niyam reads every datasheet, checks live part stock, flags lifecycle and compliance issues, and writes the fix straight into your PLM (where hardware teams store everything about a product).
Double click
An engineer uploads a Bill of Materials (BOM) - complete parts list for a circuit board - together with its schematics. Within 5 minutes Niyam:
1.Reads every linked datasheet,
2.Checks live supplier stock and lead-time data,
3.Flags end-of-life parts, thermal-limit violations, and regulatory issues (RoHS, REACH, etc.), and
4.Writes a fully documented remedy back into the company’s Product-Lifecycle-Management (PLM) system, the central “source of truth” for all revisions.
Three paid pilots show 22-30% fewer redesigns and ~$500K savings on complex boards.
Breakthroughs
Technical or conceptual advances
Million-token pass: Gemini 2.5 Pro swallows full project archives—datasheets, Gerbers, nets—in one shot, no brittle chunking.
Deterministic JSON output: OpenAI o3’s function calls turn the analysis into PLM-ready payloads.
Live part intel: Exa AI streams real-time pricing, stock, and alternates, closing data gaps.
Unlocks
What those breakthroughs make possible
Whole-dataset reasoning: entire hardware project fits in prompt—no manual pre-sorting.
PLM round-trip: model writes fixes back to the source of truth, closing the loop.
Design-to-sourcing in minutes: live stock + lifecycle checks collapse what used to take days.
Stack
What’s under the hood
Models: Gemini 2.5 Pro · OpenAI o3 · Exa AI
Services: Python + FastAPI micro-services on Modal (crawlers, rule engines, multiphysics checks)
Front-end: Next.js 15 + ShadCN/UI on Vercel
Data: Supabase (PostgreSQL + pgvector)
Still hard
What could be better
Language models struggle with extracting accurate footprints from complex datasheets that mix projections, annotations, and scale info.
Verifying 3D clearances and routing on dense boards remains mostly manual.
Reinforcement learning may be better suited than sequence models for these spatial tasks.
Why it matters
The big picture shifts
Pull → push compliance: boards get flagged before fab, not after.
Big-context hardware AI: million-token windows move mechanical/electronic design checks into LLM space.
Six-figure savings proven: pilots show real money avoided, not just nicer dashboards.
Try it
Build: Vaya – AI astrologers on demand
Builders: Maahin Puri, Nitesh Kumar Niranjan
Ask an AI-powered astrologer anything—Vaya streams your chart reading or daily forecast in seconds.
Breakthroughs
Technical or conceptual advances
Fast instruction control: Claude 3.5 Sonnet keeps tone and structure tight while staying low-latency.
“Claude 3.5 Sonnet instruction following capabilities, while reasoning models are great at thinking it can increase user facing latency.”
Local ephemeris cache: Planetary positions sit in memory, so the model never waits on an external lookup.
Unlocks
What those breakthroughs make possible
Personalised readings in under X seconds.
Multiple astrologer personas from one model backbone.
Continuous prompt/model tuning without downtime via Lighthouse (internal tool).
Stack
What’s under the hood
Runtime: Elixir (real-time streams) · Node.js/Bun · Next.js web · React Native mobile
Data: PostgreSQL · Redis · NASA JPL Ephemeris for planet positions
Infra: Kubernetes on GCP
Tooling: Lighthouse, a git-style prompt-testing harness before each deploy
Still hard
What could be better
Need lower-latency models hosted closer to India.
Occasional instruction drift and weak time references.
Emotional-tone consistency is hit-or-miss.
Why it matters
The big picture shifts
Moves astrology from booked sessions to on-tap advice.
Proves niche knowledge + controllable LLMs can power paid consumer apps