


The 10-minute AGI-proof stress test
Will your startup survive the next model drop?

Most moat talk folds after two questions. Ask why something is defensible and we—founders and investors, me included—wave our hands. Press a little and we retreat to “speed is the only moat.”
Speed matters: it gets you to market. It doesn’t keep you there.
With AI, that gap shows up fast. 48 hours after GPT-4o launched, at least three YC-style categories—note-taking bots, translation wrappers, and writing assistants—were searching for new plans. What looked shiny in March is wallpaper by June.
I wanted a quick, repeatable way to ask: “Will this startup survive the next model drop?” Nothing off-the-shelf worked, so I sketched my own “AGI-proof stress test” to use at Weekend Fund—six questions, ten minutes.
Founders: run it as a pre-mortem. See what breaks when models get smarter or cheaper.
Investors: run it to avoid funding features.
The AGI here is no sci-fi god, just a junior employee you hire for cents. If we reach true super-intelligence, this exercise will feel quaint (and that’s fine). Until then, we live in the messy middle: models keep getting better and companies still have to make money.
Traction isn’t the same as AGI-proof. Traction shows altitude. AGI-proof checks whether the wings stay on when the air thins:
• How fast can an open-weights clone match 80% of your value?
• Do margins widen or collapse when inference prices halve?
Caveats:
Deep science—fusion, new drugs, hard physics—lives or dies in the lab. I hope someone closer to those fields writes a version of this test.
Pure consumer apps live and die on network and brand. If you’re building one, weight that row heavily. If that row isn’t a 4 or 5, start there.
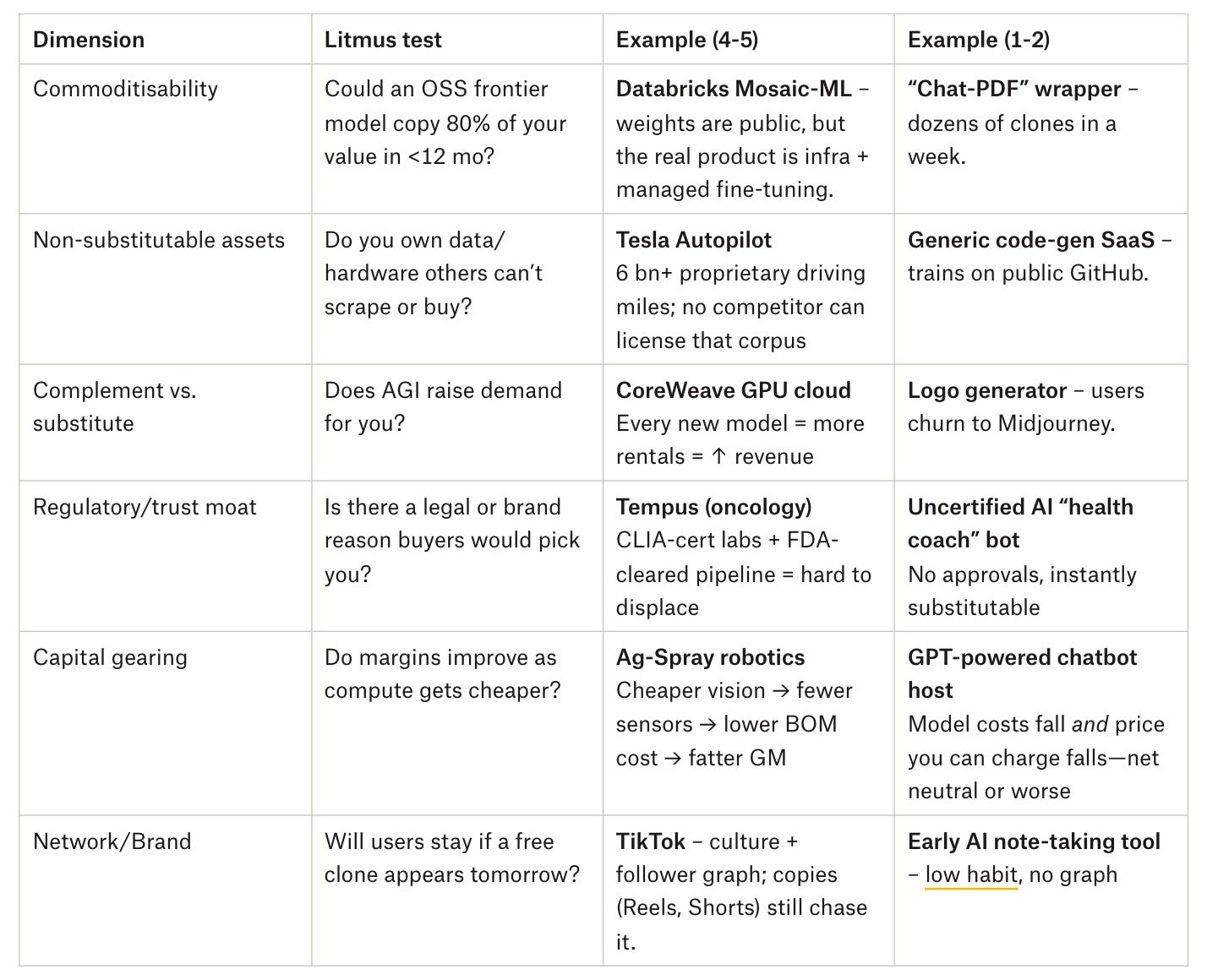
The rubric (score each row 1-5)
How to use it
Set a timer for 10 min. It’s long enough to think, short enough to force honesty.
(Optional) Assign weights. Equal weights work. If one risk worries you most, shift weight there and adjust the rest so the total stays at 100 %.
Score each row 1-5. Gut feel is fine. 1 = wide open. 5 = very hard to dislodge.
Average the scores.
< 3 → fragile
3–4 → worth deeper discussion or improving.
> 4 → likely durable, keep building
Debate only the outliers. Disagreement highlights blind spots.
If you and a co-founder/teammate differ by > 1 point on a row, dig there.
Re-run every quarter. Models evolve faster than most roadmaps.
Three real examples
I ran CoreWeave, Perplexity and a generic “prompt-wrapper copy” tool through the rubric (1 = weak, 5 = strong).
Caveats:
Low scores ≠ small outcomes. Groupon, Zynga, even early Facebook, would have looked flimsy here. The rubric measures future erosion risk, not today’s ARR.
I’m using public data. All these companies have projects I don’t have knowledge of and roadmap moves that would change their scores.
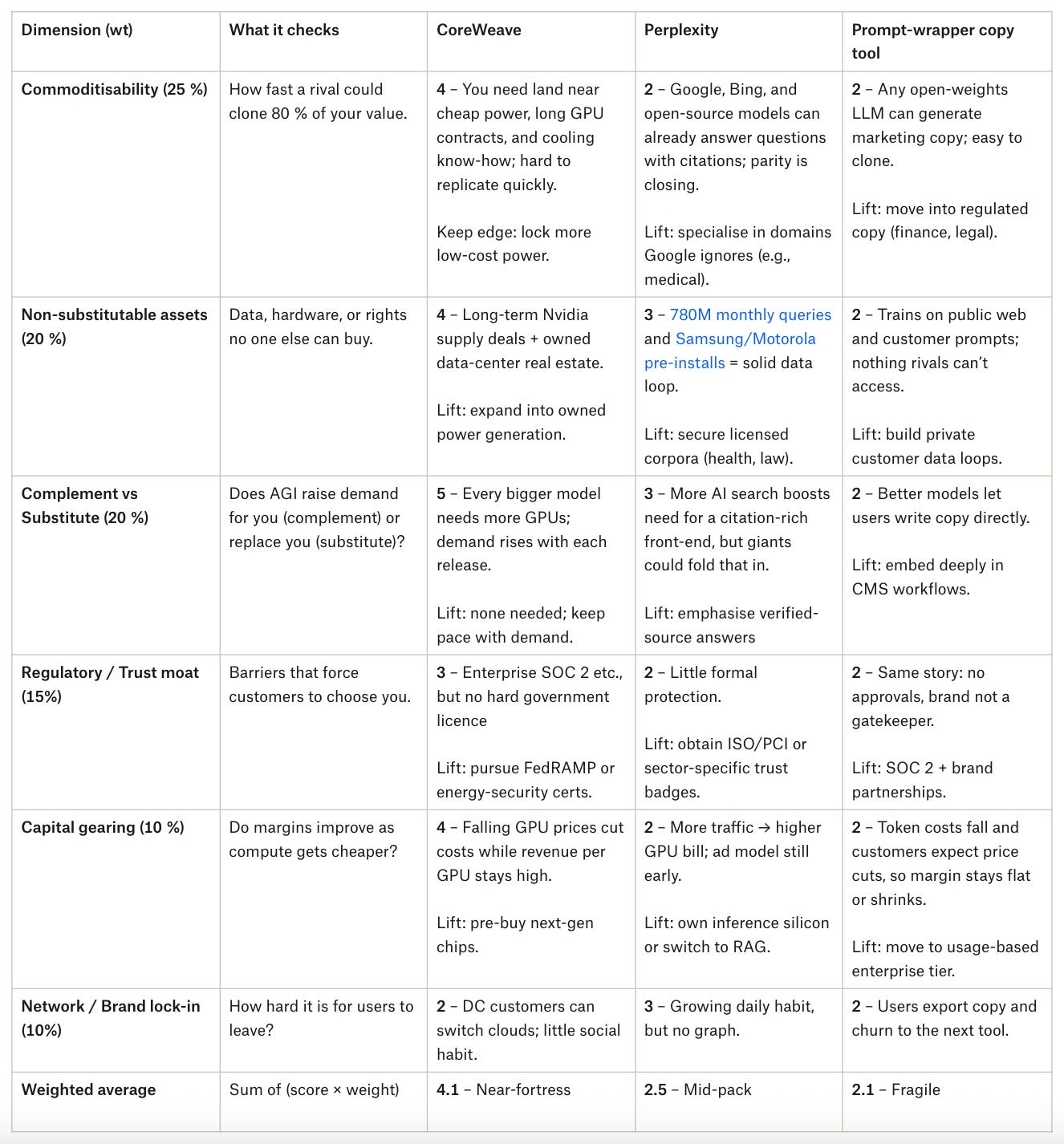
CoreWeave benefits from every bigger model and owns the GPUs; hard to unseat. Perplexity has momentum and data, but margins and exclusivity can still improve. The copy tool needs proprietary data or deeper workflow lock-in before the next leap in model quality.
Patterns we see and first moves

Steal this sheet
Here’s a google sheet template you can copy:
File → Make a copy (you must be signed in with a Google account).
Fill in the six scores. The sheet does the rest.
In closing
The rubric won’t catch every edge case, but it’s better than guessing. Spend ten minutes, find the weakest spot, patch it (or decide it can wait!) and get back to work.
Please don’t let the sheet slow you down. I’d be sad if it turned into another reason to stare at spreadsheets instead of shipping.
And remember: AGI-proof matters only after you have something people want. Product-market fit still comes first. YC’s old line holds up: “Make something people want.”
If you give it a try, I’d like to hear what you learn. I’m at vedika@weekend.fund.
Credit to Vishal Maini (Mythos Ventures) for shaping the framing—and to him and Ryan Hoover for the thoughtful draft feedback.